

使用Sovits进行语音转换(Ai唱歌)
本文最后更新于 2024-07-05,
若内容或图片失效,请留言反馈。部分素材来自网络,若不小心影响到您的利益, 请联系我 删除。
本站只有Telegram群组为唯一交流群组, 点击加入
文章内容有误?申请成为本站文章修订者或作者? 向站长提出申请
这里我选取的版本是经过魔改的Sovits"5.0"github地址,当然这不是官方的版本,而是由Sovits爱好者制作的魔改版。咳咳,不扯这么多了,接下来进入主题。
需要强调这个工具是没有一键包的,这意味着你本机需要准备前置环境。同时这里只会说明基础玩法,进阶玩法请阅读工程内的readme文件。
硬件要求
你需要一块显存不小于6gb的英伟达显卡(NVIDIA),这是硬性要求,如果没有的话那么下面的没必要再继续看了。
软件要求
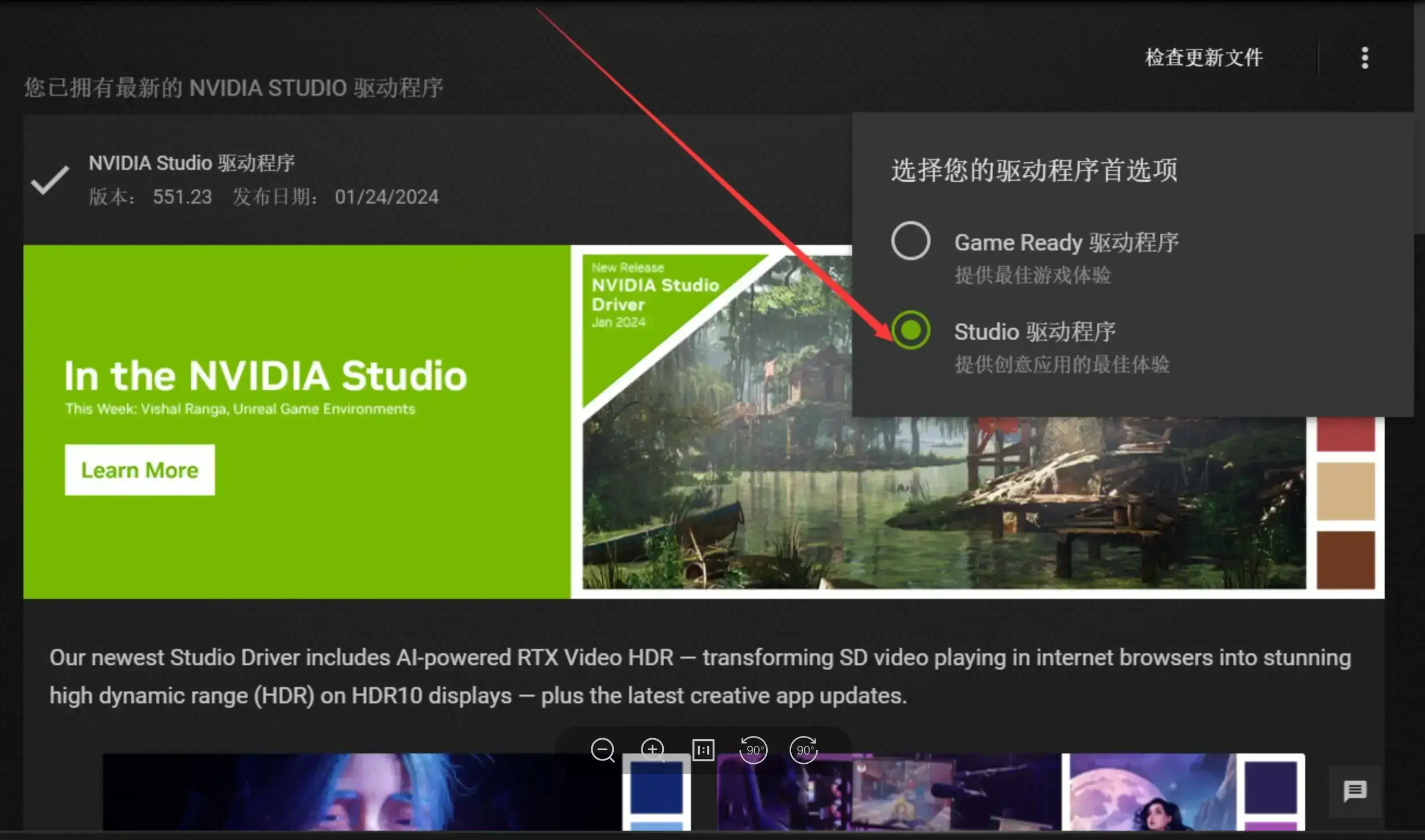
你需要检查你的英伟达显卡驱动为Studio版,如果是Game Ready版请更换为Studio版。
接下来,你需要为电脑安装cuda驱动,Cuda下载官网
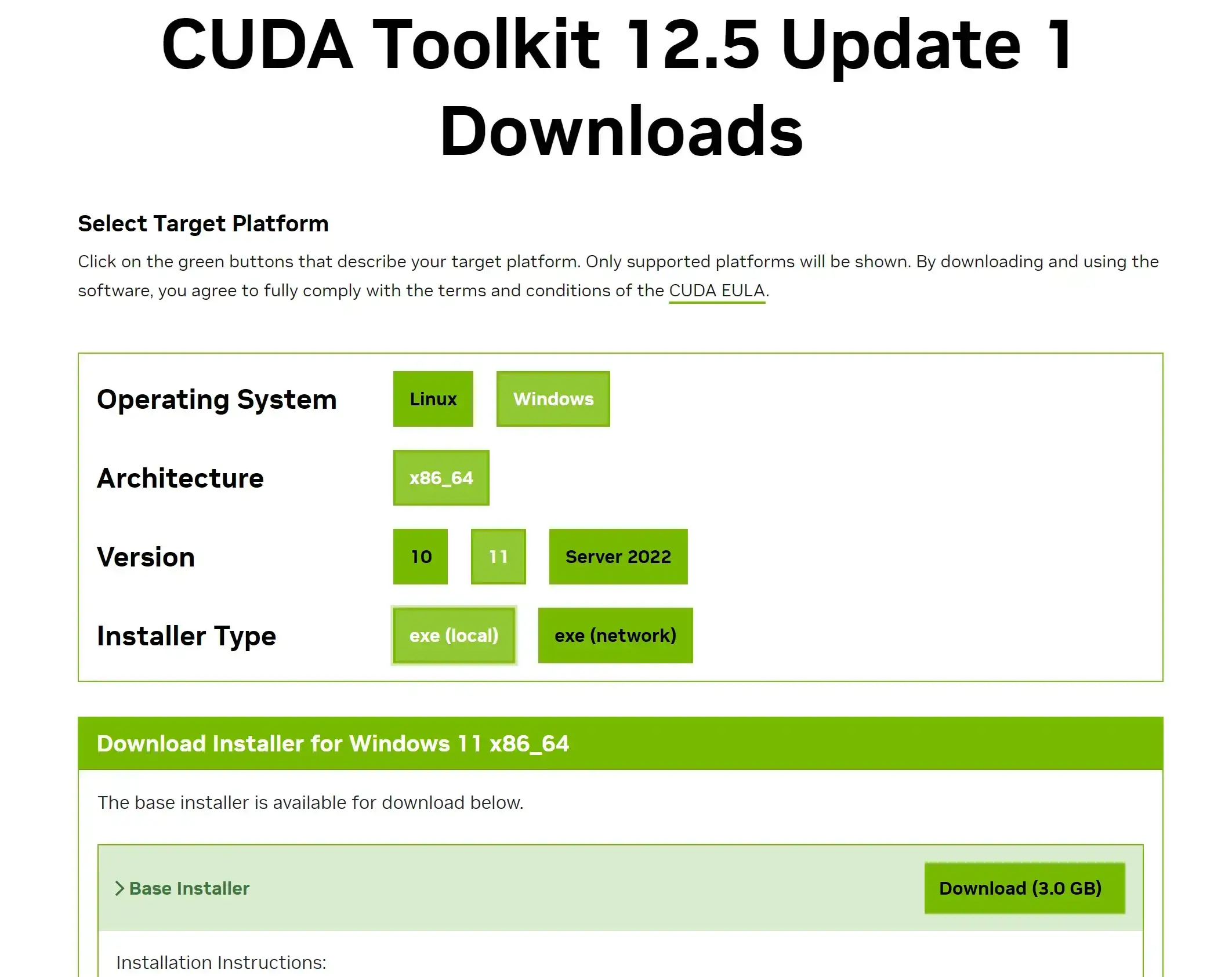
这里以我电脑为例,我的电脑显卡为3080ti,系统为windows11,这里我选择了cuda12来进行安装。安装时候你只需要一路下一步就可以。
然后你需要安装anaconda3,Anaconda3官网
同样安装只要一路下一步就可以,安装完成后关闭所有页面。打开开始菜单
打开这个终端,你可以发现在开头有base的字样代表为安装成功
开始部署
接下来你需要创建虚拟环境,这里我以python3.9为例创建一个名为pytorch的虚拟环境,创建命令:
conda create -n pytorch python=3.9
输入y然后回车
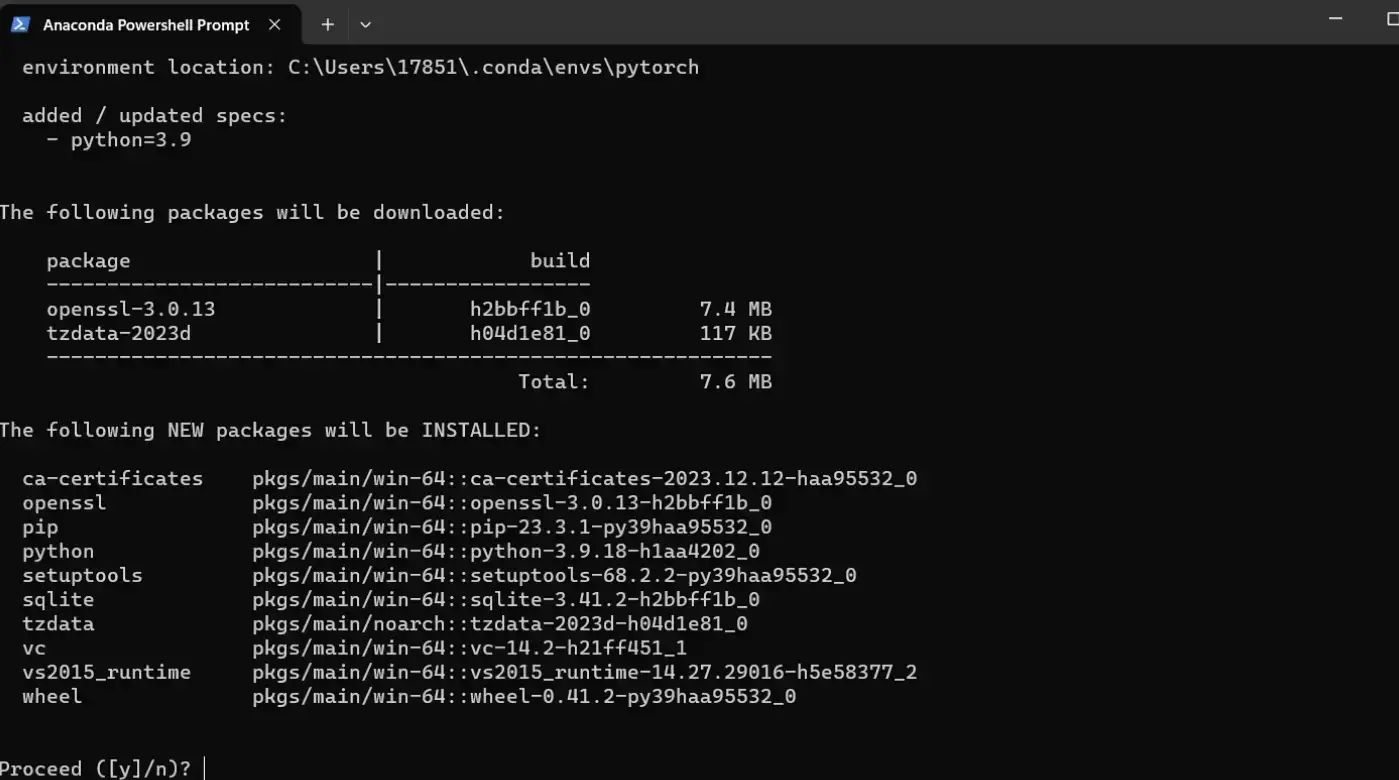
有以下提示为安装完成
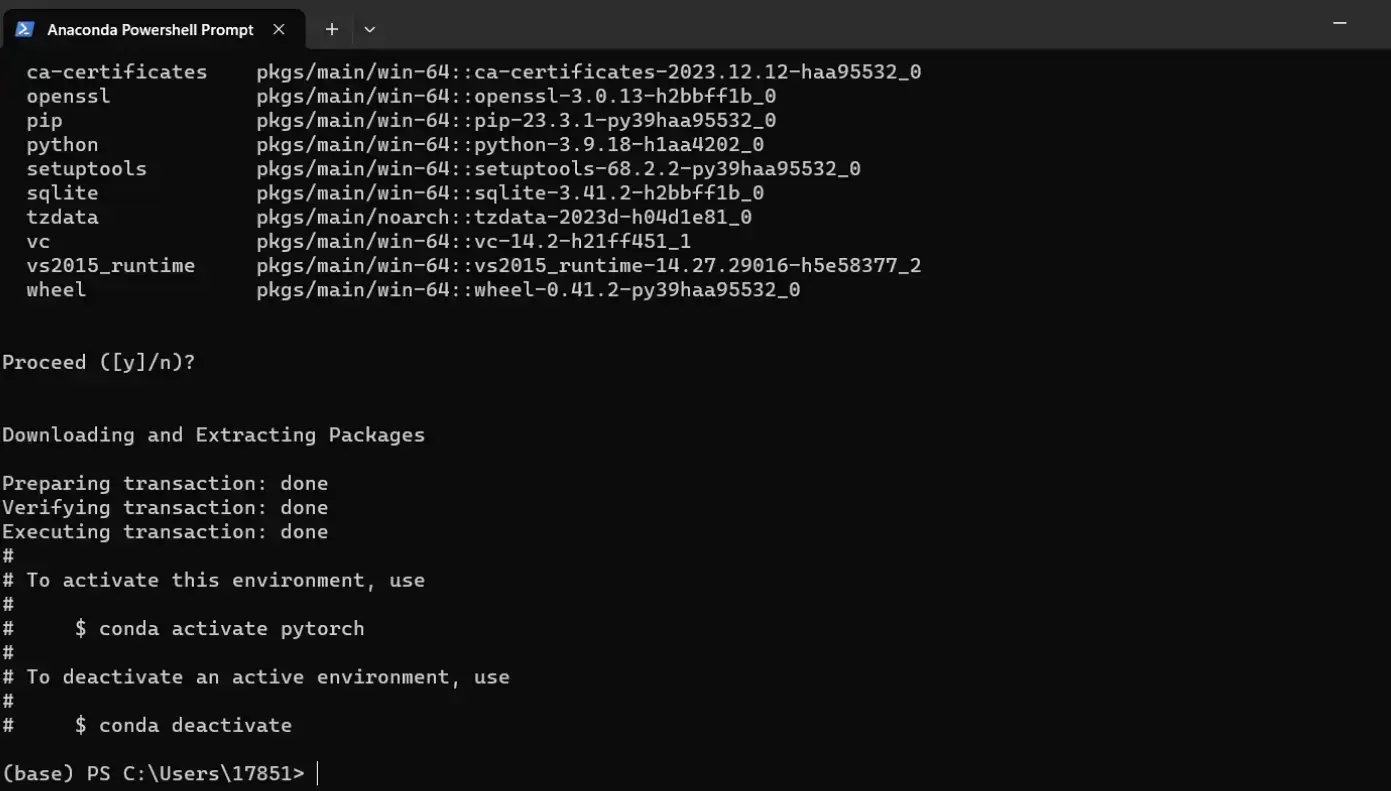
你可以输入以下命令来判断你的虚拟环境是否安装成功
conda info --envs

最后切换进虚拟环境
conda activate pytorch
 接下来你需要进入**pytorch**官网找到这个位置
接下来你需要进入**pytorch**官网找到这个位置
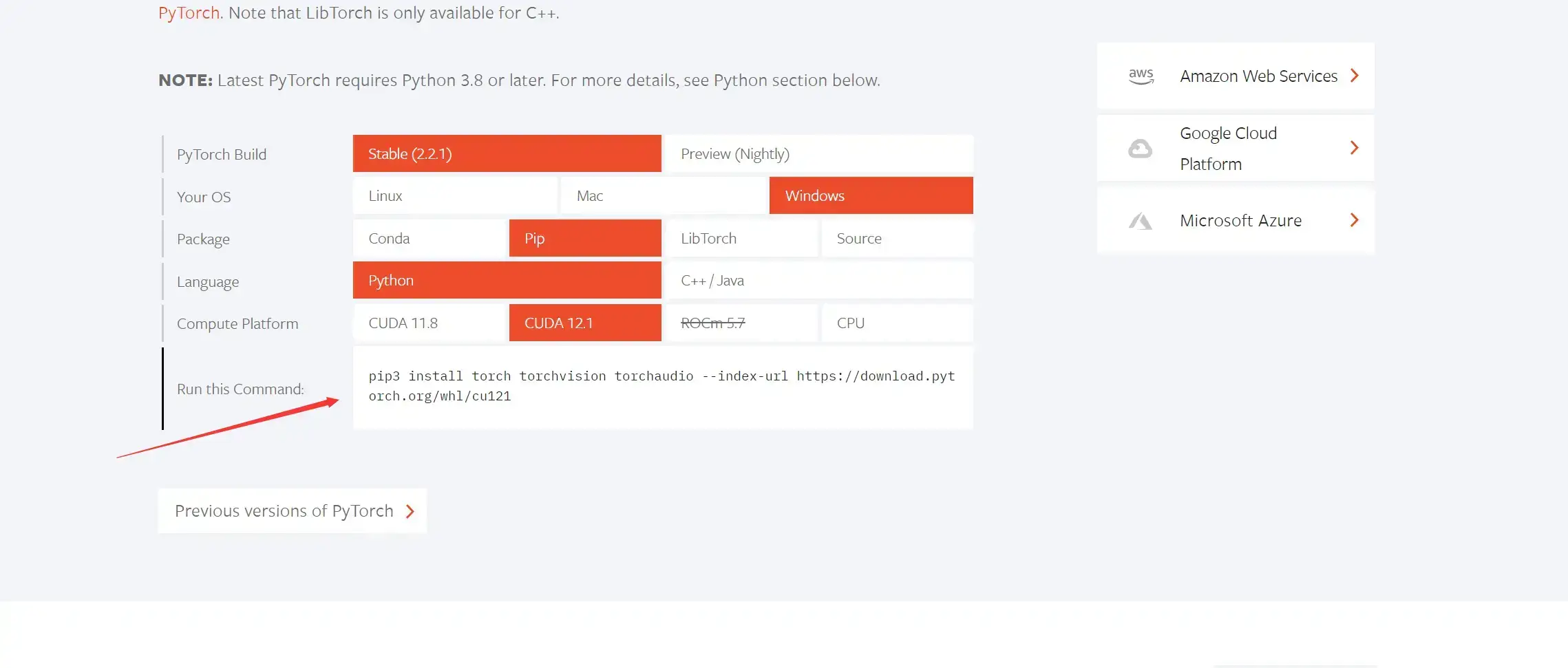
由于我安装的cuda12所以这里也要选择cuda12的版本,复制这段命令粘贴到终端。等待下载完成。

下载这个工程**github地址**并解压。进入工程目录

打开readme.md,复制以下代码到终端,回车等待下载完成。如果中途有某个包安装错误则需要打开requirements.txt文件使用pip install命令单独安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
在工程内创建文件夹dataset_raw,进入目录再创建一级文件夹(以你要训练的角色命名),这里以爱莉希雅举例
准备数据集,这部分以及使用vur分离伴奏可以通过**BV1H24y187Ko**来寻找,这里使用测试数据来演示。
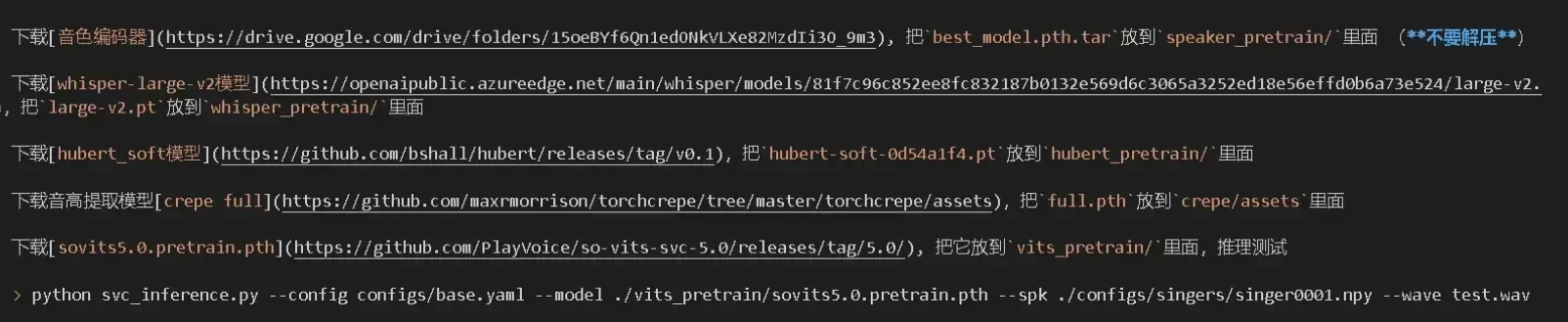
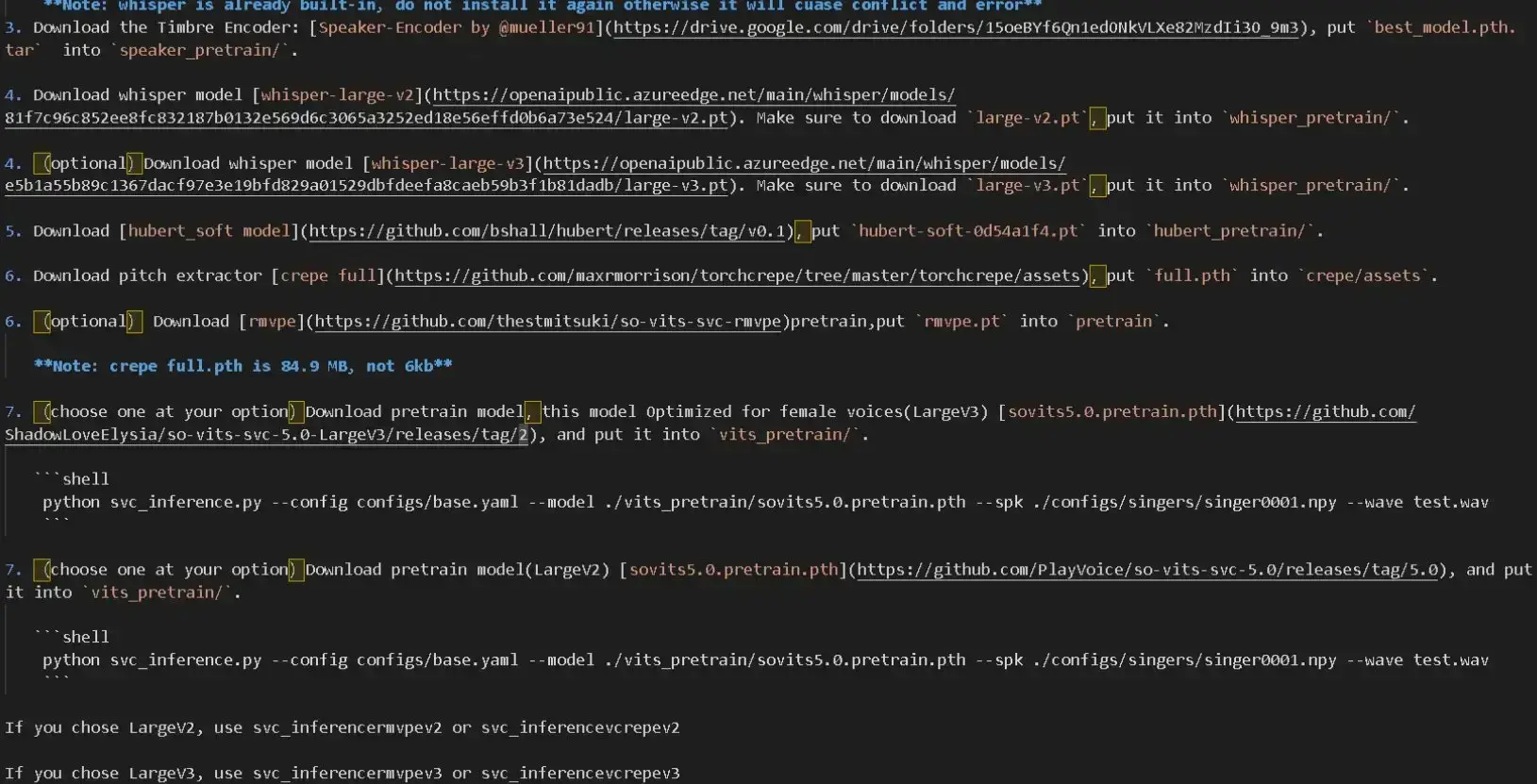
通过readme文件内的提示将底模放在对应位置,这里以v3底模测试(任选一个看)。
中文文档
英文文档
数据预处理,等待完成,处理过程中出错请仔细检查各个底模对应的位置(尤其not found类),你也可以选择手动复制命令

注意:你需要在config/base.yml中根据你显存来修改batchsize值,如果你只有6gb显存则建议你将这个值改为6或者4
开始训练
python svc_trainer.py -c configs/base.yaml -n sovits5.0
其中训练的时间由你个人决定。一般来看至少需要一天看一次,你可以通过以下命令对比real和fake来判断训练情况
tensorboard --logdir logs/
导出模型
python svc_export.py --config configs/base.yaml --checkpoint_path chkpt/sovits5.0/***.pt
这里***.pt指的是你需要对应自己的模型,请对应修改
推理(这里你需要将歌曲使用uvr分离**BV1H24y187Ko**,使用分离完成的人声推理)
python svc_inference.py --config configs/base.yaml --model sovits5.0.pth --spk ./data_svc/singer/修改成对应的名称.npy --wave test.wav --shift 0
这里你需要将npy修改为工程这个位置下的名字,推理完成输出的音频文件名svc_out.wav,你可以使用AU将人声和伴奏合成回去。
祝你使用愉快!

